Panne d'Amazon Web Services (AWS) : Comprendre le cas d’école et définir sa stratégie face aux interruptions de service
Les causes à l’origine de la panne d'Amazon Web Services (AWS)
Le lundi 20 octobre 2025, la région US‑EAST‑1 (Virginie du Nord) de AWS a connu une panne d’envergure qui a entraîné des dysfonctionnements globaux. La panne s’est déclarée à 9h11 heure de Paris.
Le point de départ a été un problème lié à la résolution DNS de l’API Amazon DynamoDB dans cette région. Plus précisément, un sous-système interne à AWS, chargé de surveiller la santé du réseau de ses load balancers, a mal fonctionné.
Le problème s’est propagé en cascade : l’API DynamoDB n’était plus joignable (ou avec forte latence), ce qui a bloqué les services qui en dépendent. de 9h30 à 10h30 CET, les premières perturbations majeures arrivent de manière généralisée. Le tableau de bord « AWS Health » indiquait alors un nombre d’erreurs en hausse et de fortes latences pour de nombreux services AWS dans la région US-EAST-1.
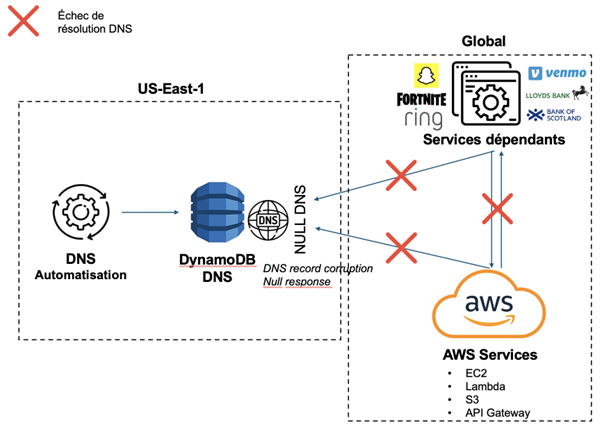
Source et impacts de la panne AWS du 20 octobre 2025
La singularité de cette panne réside dans le fait qu’elle a impacté à la fois les services externes utilisant les API DynamoDB, mais également les services AWS qui dépendent de ce service, générant une panne beaucoup plus étendue.
Amazon Web Services (AWS) a communiqué que l’ensemble des services étaient revenus à la normale à 18h01 ET le même jour (lundi), soit 00:01 mardi heure de Paris, après environ 15 heures d’impact notable. Néanmoins, certaines tâches « de rattrapage » (backlog de messages) restaient encore à traiter, pour des services comme Amazon Redshift, AWS Config, Amazon Connect. Cela signifiait une forte hausse des erreurs et des temps de réponse anormaux sur une durée plus longue, dus à un dysfonctionnement du réseau interne et du plan de contrôle.
Les services sont progressivement revenus à la normale dans la nuit de lundi à mardi.
Le bilan et l’envergure de la panne d’Amazon Web Services (AWS)
On estime que plus d’un millier d’entreprises et des millions d’utilisateurs finaux ont été affectés.
Des services très visibles tels que Snapchat, Slack, Canva, Fortnite, et des services plus « critiques » ou B2B banques ont vu des accès clients ou des transactions perturbées, avec de forts impacts financiers.
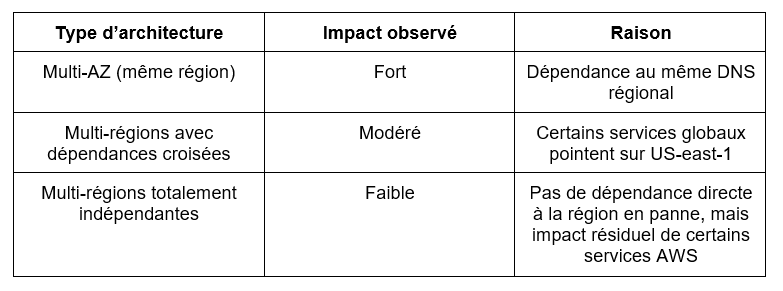
La spécificité de cette interruption de service réside dans le fait que l’impact n’a pas été limité à US-East-1, mais a affecté l’ensemble des zones d’AWS du fait des interdépendances sur certains services.
Les propres services d’AWS (ex : Amazon Alexa, Amazon site d'e-commerce) ont également subi des perturbations. Beaucoup de SaaS reposent sur des services managés d’AWS (stockage, bases, compute, API), ce qui signifie qu’une rupture dans une région centrale peut avoir des effets globaux.
Les acteurs qui disposaient d'architectures multizones ou multiclouds’en sont le mieux sortis, avec quand même des impacts pour les infrastructures distribuées. En résumé, et comme souvent dans ce type de panne, mieux les architectures sont distribuées, mois l’impact s’est fait ressentir.
Conclusion
L’importance de maîtriser sa dépendance avec les acteurs, comment réagir au mieux ?
Ce cas d’école illustre clairement que même AWS, le plus grand acteur d’infrastructure cloud, reste vulnérable, et qu’en tant que client (SaaS ou entreprise) vous partagez et acceptez ce risque.
Dépendre massivement d’un unique « hyperscaler » pose trois grands risques :
Un point de défaillance unique à l’échelle de l’entreprise ou de l’écosystème, même sur une infrastructure distribuée
Un risque économique de dépendance fournisseur et de pratiques commerciales changeantes
Un risque stratégique et géopolitique sur la règlementation pratiquée et les politiques de confidentialité
Ce constat implique qu’il est fondamental d’avoir une politique en accord avec votre stratégie et les risques que vous vous permettez d’accepter pour vos infrastructures. Du point de vue européen ou pour les entreprises sensibles en Europe, cela pose également la question centrale de la souveraineté : qui contrôle l’infrastructure, les données, quelle localisation, quelle dépendance extraterritoriale ?
L’observabilité des infrastructures joue par ailleurs un rôle essentiel pour contrôler en temps réel la santé de votre SI, mesurer l’impact d’une panne, et obtenir l’ensemble des informations utiles pour réagir efficacement et de la meilleure manière.
Vous réfléchissez à réduire votre dépendance aux service providers américains ? Nous avons récemment réalisé une étude sur la souveraineté européenne et la dépendance américaine.
Vous êtes intéressé pour mettre en place de l’observabilité sur vos infrastructures Cloud ou hybrides ? Nous pouvons vous accompagner sur ce sujet.
N’hésitez pas à contacter Navigacom pour échanger avec nos experts et nous parler de vos problématiques.
NEWSLETTER
Ne manquez rien !
Vous avez aimé cet article ? Abonnez-vous à notre newsletter pour recevoir directement dans votre boîte mail des conseils, des astuces, et les dernières nouveautés du cabinet.
Inscrivez-vous maintenant et restez informé !